
En el año 2005 egresó de la Facultad de Ciencias de la Universidad de la República (Udelar) como licenciado en Ciencias Biológicas. Posteriormente, se recibió como magíster y doctor en Ciencias Biológicas en los años 2009 y 2014, respectivamente, en el Programa de Desarrollo de las Ciencias Básicas (Pedeciba) de la Udelar.
Desde el año 2014 es docente de la Facultad de Piscología y en la actualidad es el coordinador del programa Ciencia de Datos y Psicometría, perteneciente al Instituto de Fundamentos y Métodos en Psicología. También es el investigador del Centro de Investigación Básica en Psicología (CIBPsi), e integrante del Centro Interdisciplinario en Ciencia de Datos y Aprendizaje Automático (CICADA). Anteriormente fue docente en la Sección Biofísica de la Facultad de Ciencias de la Udelar.
Su actividad de investigación se orienta hacia el estudio de las bases neurobiológicas de la facultad del lenguaje, a través de experimentos psicofísicos y la ciencia de datosps. En particular se enfoca en explorar las diferentes dimensiones psicolingüísticas del léxico, con énfasis en el significado. Por ejemplo, su iniciativa “Proyecto lexicón” (www.lexicon.uy) busca construir representaciones matemáticas el significado de las palabras a través del análisis de datos experimentales, tales como la asociación de palabras, o aplicando técnicas de aprendizaje automático a grandes cantidades de texto.
Entre sus múltiples trabajos de producción científica y tecnológica destaca su participación en la redacción de los artículos arbitrados “The ‘Small World of Words’ free association norms for Rioplatense Spanish”, “A modular neural model that implements probabilistic topics” y “Detecting order-disorder transitions in discourse: implications for schizophrenia”.
Línea de investigación:
Estudio de los mecanismos neurales que subyacen a la toma de decisiones de acercamiento-evitación social en depresión
Centros de investigación:
Centro de Investigación Básica en Psicología
- Neurociencia Cognitiva y Salud Mental
- Procesamiento léxico
Instituto de Fundamentos y Métodos en Psicología
Dirección: Tristán Narvaja 1674 (EDIFICIO CENTRAL)
Ubicación: NIVEL 2
Teléfono: (598) 2400 8555
Interno: 340
Centro de Investigación Básica en Psicología (CIBPsi)
Dirección: Tristán Narvaja 1674 (EDIFICIO CENTRAL)
Ubicación: NIVEL 2
Teléfono: (598) 2400 8555
Interno: 285 y 286

Se recibió como licenciada en Biología Humana la Universidad de la República (Udelar) en el año 2010. En el año 2015 egresó como magíster en Ciencias Biológicas del Programa de Desarrollo de las Ciencias Básicas (Pedeciba) de la Udelar y en 2021 se doctoró en el Programa de Lingüística (actualmente, Programa en Neurociencia Cognitiva) en el Basgque Center on Cognition, Brain and Language (BCBL) y la Universidad del País Vasco, España.
En el año 2012 ingresó a la Facultad de Psicología como técnica de laboratorio del Centro de Investigación Básica en Psicología (CIBPsi) y actualmente es integrante del programa Ciencia de Datos y Psicometría del Instituto de Fundamentos y Métodos. Además, se desempeña como investigadora en el Centro de Investigación Básica en Psicología (CIBPsi) y en el Centro Interdisciplinario en Cognición para la Enseñanza y el Aprendizaje (CICEA).
Su principal tema de interés y de producción científica son las bases neurocognitivas del aprendizaje de la lectura en niños y su vinculación con el desarrollo del lenguaje. En este campo, desarrolló la aplicación “Lexiland”, destinada a predecir el riesgo lector, y aportó con su trabajo a la comprensión de los principales predictores del desempeño lector en español, así como sus bases neurales.
Cuenta con diversas publicaciones, dentro de las cuales destacan los artículos arbitrados “Lexiland: a Tablet-based Universal Screener for Reading Difficulties in the School Context”, “Mind the orthography: revisiting the contribution of prereading phonological awareness to reading acquisition” y “A Translational Framework of Educational Neuroscience in Learning Disorders".
Línea de investigación / Grupo de investigación: Lectura: aprendizaje, bases neurocognitivas y dificultades.
Centros de investigación: CIBPSI (Centro de Investigación Básica en Psicología)
Instituto de Fundamentos y Métodos en Psicología
Dirección: Tristán Narvaja 1674 (EDIFICIO CENTRAL)
Ubicación: NIVEL 2
Teléfono: (598) 2400 8555
Interno: 340
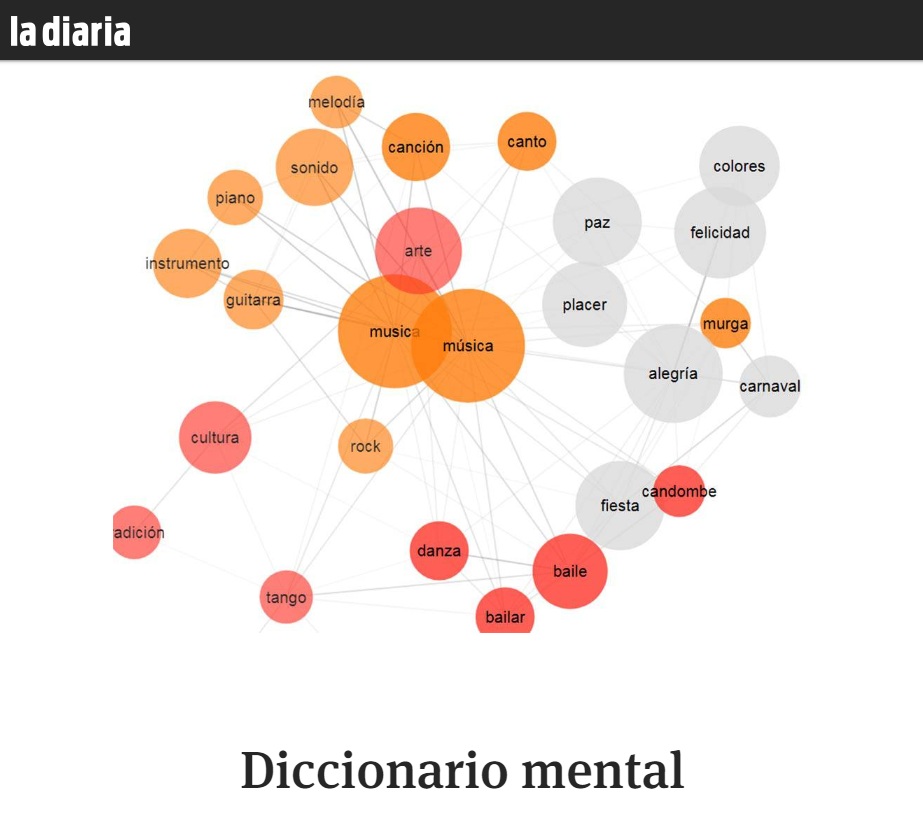
Lexicón. Un proyecto que involucra a la Facultad de Psicología de la Udelar, en colaboración con la Universidad de Melbourne, propone un juego virtual para determinar cómo se procesa el lenguaje.
“Queremos saber cómo funciona el cerebro. Hacemos experimentos para estudiar el significado de las palabras. Hacemos redes neurales artificiales. Y nos gusta”, figura en el perfil de Twitter de Proyecto Lexicón (@lexicon_uy). Lo que buscan es ver cuáles son las asociaciones más comunes para una palabra dada e intentan así elaborar un mapa de vecindades o similitudes entre vocablos. El experimento que llevan adelante Álvaro Cabana, Camila Zugarramurdi y Juan Valle Lisboa, desde el Centro de Investigación Básica en Psicología de la Facultad de Psicología, convoca a participar en forma virtual en un juego que implica unos pocos minutos. Es la forma de sumarse a una investigación que desde 2014 se desarrolla en colaboración con la Universidad de Melbourne (Australia) pero que hace unos meses, con ayuda de las redes sociales, cobró nuevo impulso. Busca “recabar información acerca del uso de las palabras del español rioplatense en hablantes nativos para construir una Norma de Asociación Libre del Español Rioplatense que tome en cuenta miles de palabras propias de la variedad dialectal que hablamos en nuestro país”. En la red del pajarito utilizan la imagen de Pinky (de la serie animada Pinky y Cerebro) con un mate y un termo bajo el brazo, ya que en este caso cada participante funge como ratón de laboratorio.
Se puede jugar más de una vez, porque a los efectos del experimento, es igualmente útil, explica Álvaro Cabana: “Funcionamos por tandas de 1.000 palabras. A vos te aparece un pool de 18 palabras tomadas de 1.000. Si entrás de vuelta, probablemente te toquen otras. Y dentro de un mes capaz que ya hay otras 1.000 nuevas. La muestra es al azar, pero cuando llegamos al nivel bueno de respuestas para cada una de esas preguntas, vemos cuáles son las más frecuentes que formaron parte de la colecta y las ponemos de vuelta. Mantenemos la validez ecológica, por así decirlo, del estudio. No inventamos palabras nosotros; son las palabras que la gente puso”.
Por eso, cuenta, tienden a aparecer “che”, “bo”, nombres propios –Juan, María, Mujica, Macri– y aunque sugieren no armar frases, la idea es no reprimir demasiado la respuesta. Si bien el tiempo de reacción del usuario queda registrado, por ahora no toman en cuenta ese dato. “Vemos que es como si la gente se pusiera chaleco, camisa y corbata para escribir, usa un registro formal, y lo que más nos interesa es que hable como habla espontáneamente, en la cotidiana, en confianza. Entonces, aparentemente la gente escribe más ‘dinero’ que ‘plata’. Me llamó la atención; con cualquier otra cosa, no: la gente dice ‘pelota’ no ‘bola’, ‘auto’, no ‘coche’, escribe ‘balde’ y no ‘cubo’”.
Actualmente tienen 1.300.000 respuestas individuales y la primera tarea consiste en contar cuál es la palabra más frecuente para cada palabra (para ‘silla’ es ‘mesa’, por ejemplo). Antes de pasar a una etapa de análisis, para sistematizar los datos correctamente tienen que interpretar lo que los participantes quisieron decir. “Tenemos que supervisar ese proceso porque no está registrando lo que la gente dice sino lo que la gente escribe; entonces, el problema es que para la computadora la mayúscula es una cosa, la minúscula es otra, y tenés que corregir o estandarizar la grafía”. Es necesaria esa “curaduría manual” de los resultados, ya que a veces son ambiguos. “Algunas podés corregirlas automáticamente, pero a veces no sabés si quiso decir ‘jugo’ o ‘jugó’. Los tildes son importantes y la gente casi nunca los pone”.
¿Para qué servirá esta base de datos? En principio es una herramienta de investigación. “Si trabajás en lenguaje, trabajás con muchas entidades; una de ellas son las palabras, que tienen millones de cualidades distintas: frecuencia –hay palabras raras y comunes–, tienen categoría gramatical, tienen imaginabilidad –una manzana, y otra cosa más abstracta, como la libertad, no tienen la misma–. A la hora de diseñar un experimento tenés que saber que unas palabras se conectan con otras y cómo es en tu comunidad de hablantes, en nuestro caso, el español rioplantense. Esa es la cosa más técnica; después podés hacer millones de cosas con esos datos. Una de ellas es construir una representación de palabras, un modelo de patrones de asociación en una computadora. Y nosotros tenemos información demográfica, como edad, sexo, nivel educativo, y podés jugar con esas cosas. Si ves los patrones de asociación de ‘niño’ y de la palabra ‘niña’ son parecidos, pero en el caso de ‘niña’ aparecen palabras relacionadas a la belleza física o a la vestimenta, el estereotipo básico. En ‘señor’ aparece mucho más la autoridad que en ‘señora’, cuando aparecen roles de género. Ese tipo de cosas podés analizarlas con otro ojo”.
Una vez finalizado el trabajo los datos serán públicos y para usos no comerciales o simplemente para curiosear, porque surgen cosas divertidas: “si ponés ‘Macri’ aparece ‘gato’”. También se hace notoria la penetración anglosajona: de las últimas 1.000 palabras hubo diez en inglés, como password.
Cabana calcula que hacia abril o mayo del año que viene estará en condiciones de escribir un artículo con la primera tanda de resultados. La idea es llegar a tener mapeadas 10.000 palabras (que tiene una correlación cercana a las 1.600.000 respuestas).
Para participar en el proyecto: smallworldofwords.org/uy/introduction En la plataforma www.lexicon.uy/ver se puede navegar, en una representación amigable, los datos recabados hasta ahora.